Now that we’ve established what the trip planning app is and what it should do, the natural next question is: where does all the data come from? We’ll look under the hood in this post, and I’ll walk through a few of the technical details that power the app. Every activity you see in the trip planner — from hikes and local events to scenic drives and places to grab a bite — is gathered from publicly available information. While a lot of the restaurants, trails, events, etc. the user interacts with is carefully curated, we use a combination of crawlers, scrapers, and APIs as a starting point to gather and organize the initial data.
Tool #1: Crawlers

Crawlers are automated tools that browse the web and collect information, much like what Google does when it indexes web pages. In our case, we use crawlers to discover new content — everything from hiking trail descriptions and park alerts to local event pages. We’re not crawling the web for new pages since this runs the risk of introducing unreliable data, so these bots explore a list of known and trusted websites, gathering new content that we can then filter and format for our app.
For example, city tourism boards and regional visitor sites frequently post updated schedules, calendar events, and activities — perfect fodder for our crawlers. Crawlers help us scan this content automatically, and find new pages and look for new links, and so on.
Tool #2: Scrapers
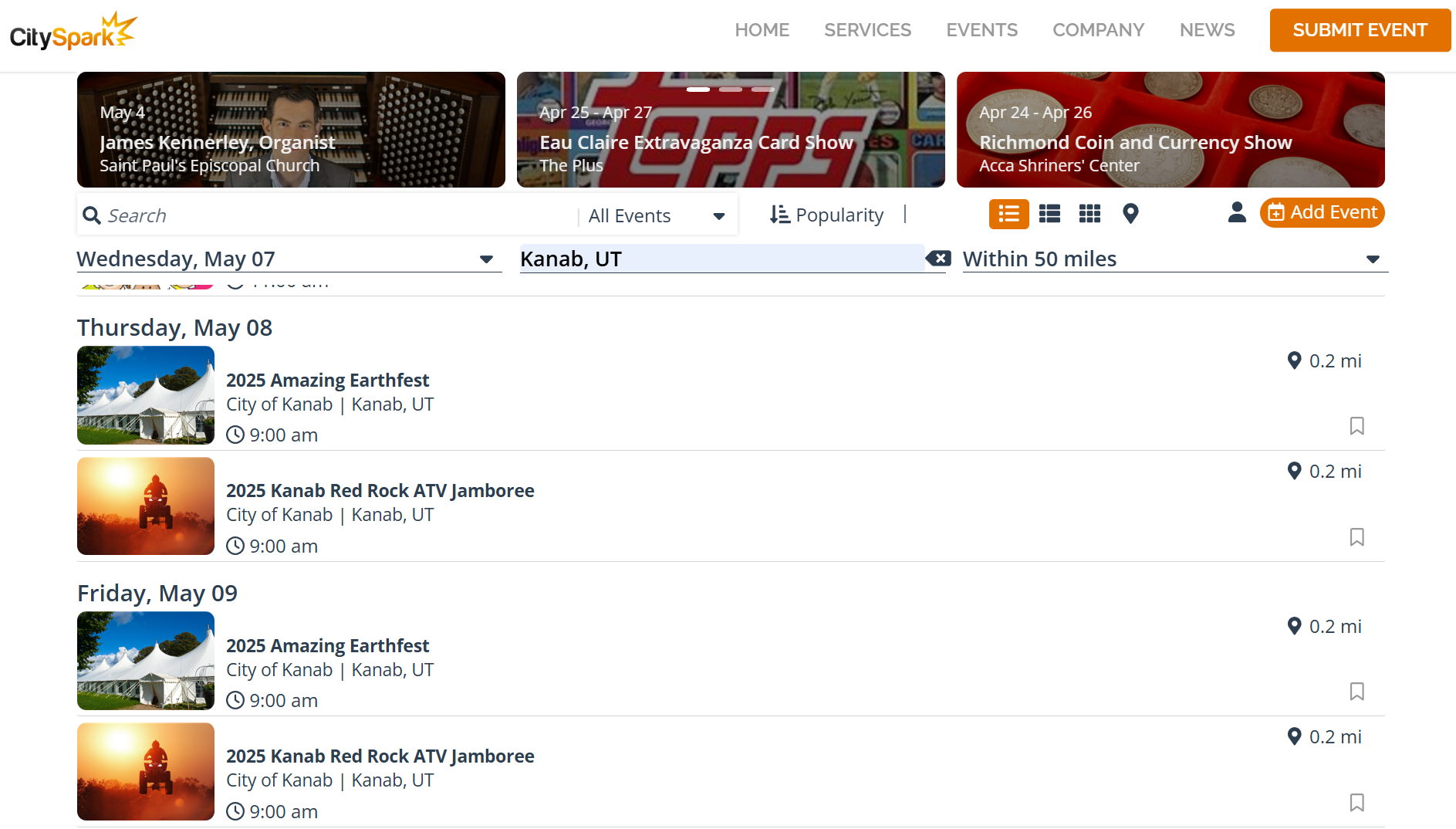
Scrapers help turn the raw content we’ve found from the crawlers into usable formats. Scraping is especially useful when sites don’t offer APIs but display rich data right on the page — think restaurant web sites and menus or community calendars. For example, to gather events in Kanab, the app uses a scraper that finds all CitySpark events such as festivals, concerts, and other occurrences in southern Utah and pulls anything that might be interesting for visitors to Kanab and the surrounding national parks. Our scraper extracts relevant pieces like event names, addresses, dates, hours, descriptions, and more, and cleans them up for use in our system.
Another good example of data we scrape is from the National Park Service web site. While some of their data is API-accessible, other details (like seasonal trail closures or current conditions) live in static HTML pages. We use scrapers to routinely collect and format this information to keep our listings accurate and up-to-date.
Tool #3: APIs
APIs, or Application Programming Interfaces, are the preferred way to gather data. When available, they’re structured, efficient, and often updated in real-time. Here’s a sampling of the APIs we’re using, and this is by no means a comprehensive list:

- Google Cloud Vision API for extracting text from images, and identifying image content.
- Google Maps API for calculating travel distances. A variety of maps are available for the trails, which I’ll share more information about in a later post.
- Google Places API for cataloging businesses and locations in the area, including open hours and web sites.
- National Park Service APIs for park alerts, trail information, and visitor center locations.
- National Weather Service APIs for forecasting weather and adjusting itineraries as necessary.
- TripAdvisor APIs for gathering reviews of different locations.
- USGS datasets, which include comprehensive GIS data for national park trails (like Zion and the Grand Canyon).
- Utah’s Open Data portal, which provides datasets on trails, camp sites, state park visitor counts, water levels, flood warning zones, fish stocking, and more.
Overall, these APIs offer a rich source of structured data that we can query, cache, and cross-reference with other data sources to build a more complete picture of the area.
The Tech Stack: What Powers the Planner
Here’s a quick rundown of our architecture:
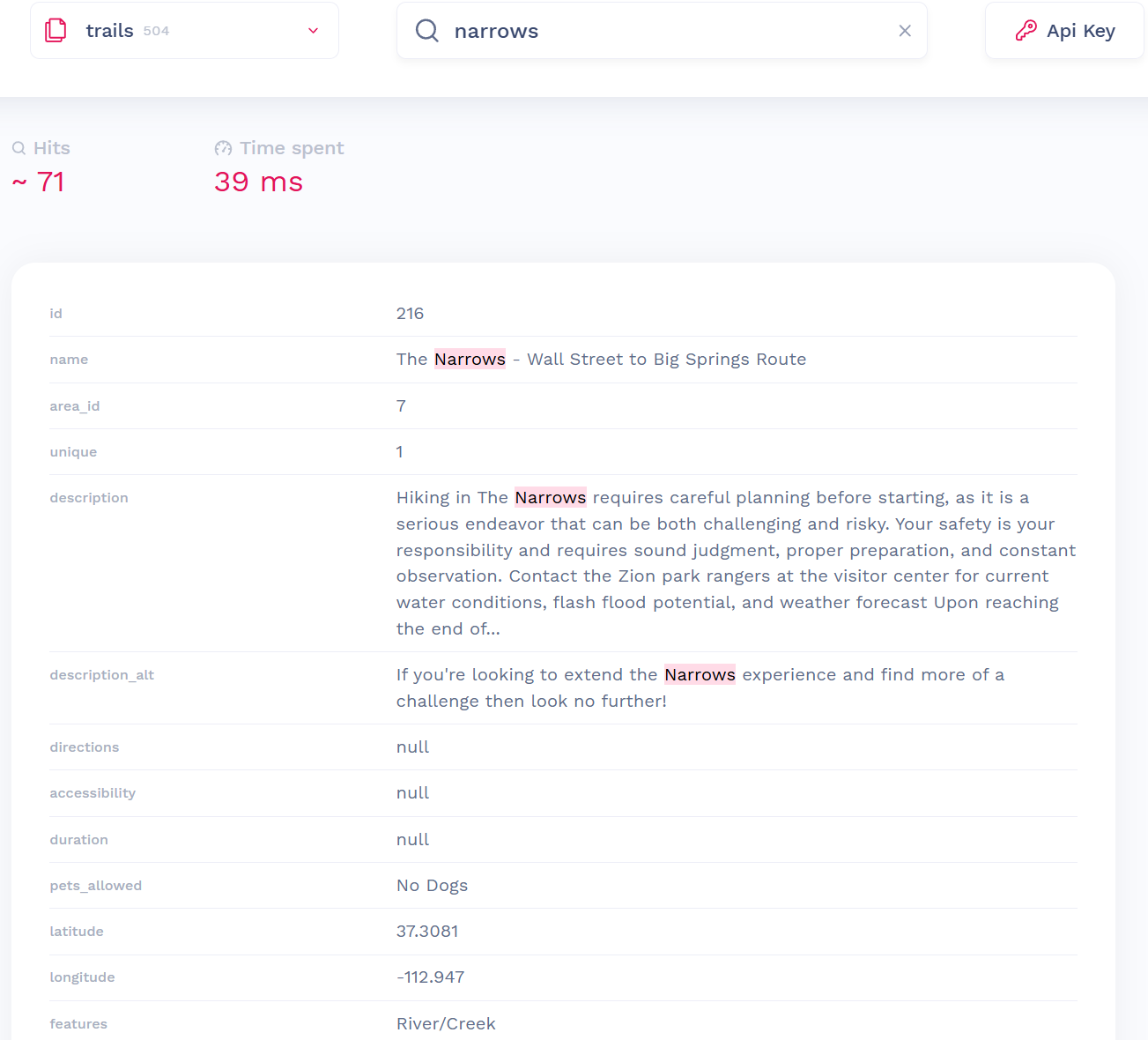
- Frontend: Built in Vue.js, our user interface (UI) is designed to be fast, clean, and responsive — whether you’re browsing on your phone in a tent or planning from your desktop at home. DaisyUI provides many of the UI components across the site.
- Backend: Laravel powers our API and handles user authentication, trip planning logic, and integrations with external data sources.
- Database: MySQL stores most of our structured content.
- Search: For full-text search and recommendations, Meilisearch is a lightweight yet robust search engine that integrates nicely with Laravel, and gives us lightning-fast results with typo-tolerance and relevancy scoring. This was chosen over other options like Elasticsearch for its simplicity and ease of integration.
- Cache & Processes Monitoring: Redis is used for caching frequently requested data, as well as queuing and monitoring background jobs like data syncing or content processing.
- AI Integration: We’ve trained a custom AI model using a vast dataset of local information — trails, restaurants, event schedules, points of interest, and more. This model in many ways is the heart of the Kanab trip planner, fully integrated across the app, powering intelligent recommendations and our in-app assistant. In an upcoming post, I’ll break down how the assistant uses this model to answer your questions in real-time and help build an itinerary tailored to your interests and physical activity preferences.
This high-level overview should give you a sense of how the trip planning app pulls together a diverse range of data into a single, easy-to-use interface. In future posts, we’ll go deeper into some of these APIs and how we structure the data we gather, as well as how we use AI to organize it. I’ll also discuss how we’re leveraging the web app into a mobile app for both Android and iOS, and even providing offline functionality.